




ในระยะเวลาหลายปีที่ผ่านมา เครื่องแมคกับการเล่นเกม คือสองสิ่งที่แทบจะไม่สามารถมาบรรจบกันได้เลย แม้จะมีความพยายามในการพอร์ตเกมลง macOS จากทางฝั่งนักพัฒนา รวมถึงแพลตฟอร์มใหญ่ในตลาดอย่าง Steam ที่มีการเพิ่มเกมที่เล่นได้บนแมคลงไปให้ซื้อหามาเล่นกันได้ก็ตาม แต่สิ่งที่เป็นอุปสรรคใหญ่เสมอมาคือจากทั้งฮาร์ดแวร์ที่มักจะไม่ได้มีกราฟิกชิปแรง ๆ มาให้ในรุ่นใช้งานทั่วไป ประกอบกับตัวเครื่องที่เน้นความบาง ส่วนฝั่งซอฟต์แวร์อันนี้ก็ยิ่งหนักขึ้นไปอีก เพราะมันแตกต่างจาก Windows เป็นอย่างมาก แต่พอมาในยุคปี 2023 ที่ Apple เปิดตัวชิป M3 ในแมค รวมถึงชิป A17 Pro ใน iPhone 15 Pro ทาง Apple ได้นำเสนอเรื่องการเล่นเกมแบบจริงจัง รองรับ ray tracing รวมถึงยังประกาศว่าผลิตภัณฑ์ของตนเองสามารถใช้เล่นเกมระดับ AAA ได้เหมือนกับพีซี Windows และเครื่องเกมคอนโซลด้วย

ซึ่งส่วนที่เป็นปัจจัยสำคัญก็คือ GPU ที่อยู่ในทั้งชิป M3 และ A17 Pro ที่มีการพัฒนาขึ้นในทุก ๆ ปี ประกอบกับตัว OS เองก็ได้รับการพัฒนาให้สามารถพอร์ตเกมมาลงได้ง่ายขึ้นด้วย (วิธีทำให้ Mac เล่นเกมได้ผ่าน GPTK) ในบทความนี้เราจะมาเจาะลึกเทคโนโลยีใน GPU ที่ช่วยเพิ่มประสิทธิภาพด้านกราฟิกกัน ซึ่งเป็นข้อมูลจากเซสชันบรรยายของ Apple เอง โดยคุณ Jedd Haberstro ที่ดูแลด้าน GPU กราฟิกและซอฟต์แวร์ที่เกี่ยวกับการแสดงผล

ในการประมวลผลกราฟิก Apple จะใช้ API ของตนเองที่มีชื่อว่า Metal ทำงานโดยใช้โค้ดภาษา Metal Shading Language (MSL) ที่มีรากฐานมาจาก C++14 แต่ในรอบนี้จะมีการยกระดับความสามารถในการคำนวณขึ้นไปอีก ด้วยการปรับปรุงฮาร์ดแวร์และระบบจัดการ ให้สามารถคำนวณ shading จำนวนมากกว่าเดิมไปพร้อมกันได้ในลักษณะของคู่ขนาน โดยอาศัยการประมวลผลของ Shader core ที่มีอยู่ใน GPU
แต่ละ shader core เอง มีความสามารถในการทำงานได้หลายพันเธรดพร้อมกันแบบคู่ขนาน ทำให้ถ้าหากสามารถกระจายงานไปให้แต่ละคอร์ได้ดี มีการแชร์ทรัพยากรร่วมกันที่เหมาะสม ก็จะทำให้ประสิทธิภาพในการเรนเดอร์กราฟิกสูงขึ้นตาม ประกอบกับแนวทางการออกแบบชิป Apple Silicon ในแต่ละรุ่นย่อย เช่น M3, M3 Pro และ M3 Max ก็ใช้เป็นการสเกลปริมาณคอร์ แคชขึ้นไปเรื่อย ๆ ถ้าให้เห็นภาพง่ายก็คือเหมือนเอาชิป M3 มา แล้วเอา p-core, e-core และ GPU มาแปะเพิ่มเข้าไป ซึ่งก็จะยิ่งช่วยเพิ่มประสิทธิภาพขึ้นไป เมื่อมีจำนวนคอร์ GPU เพิ่มขึ้น นอกจากนี้ Apple ยังได้มีการปรับปรุง GPU ของชิป M3 และ A17 Pro จากภายในด้วย 3 ประเด็นหลัก เพื่อทำให้รองรับการประมวลผลกราฟิกที่ซับซ้อนขึ้น และมีประสิทธิภาพโดยรวมสูงกว่าเดิม ได้แก่

- การปรับปรุงส่วนของ shader core ใหม่
- เพิ่ม ray tracing ในระดับฮาร์ดแวร์
- ปรับปรุง mesh shading ในระดับฮาร์ดแวร์
เรามาเริ่มดูกันทีละข้อครับ
การปรับปรุง Shader Core ใน GPU ของชิป M3 และ A17 Pro
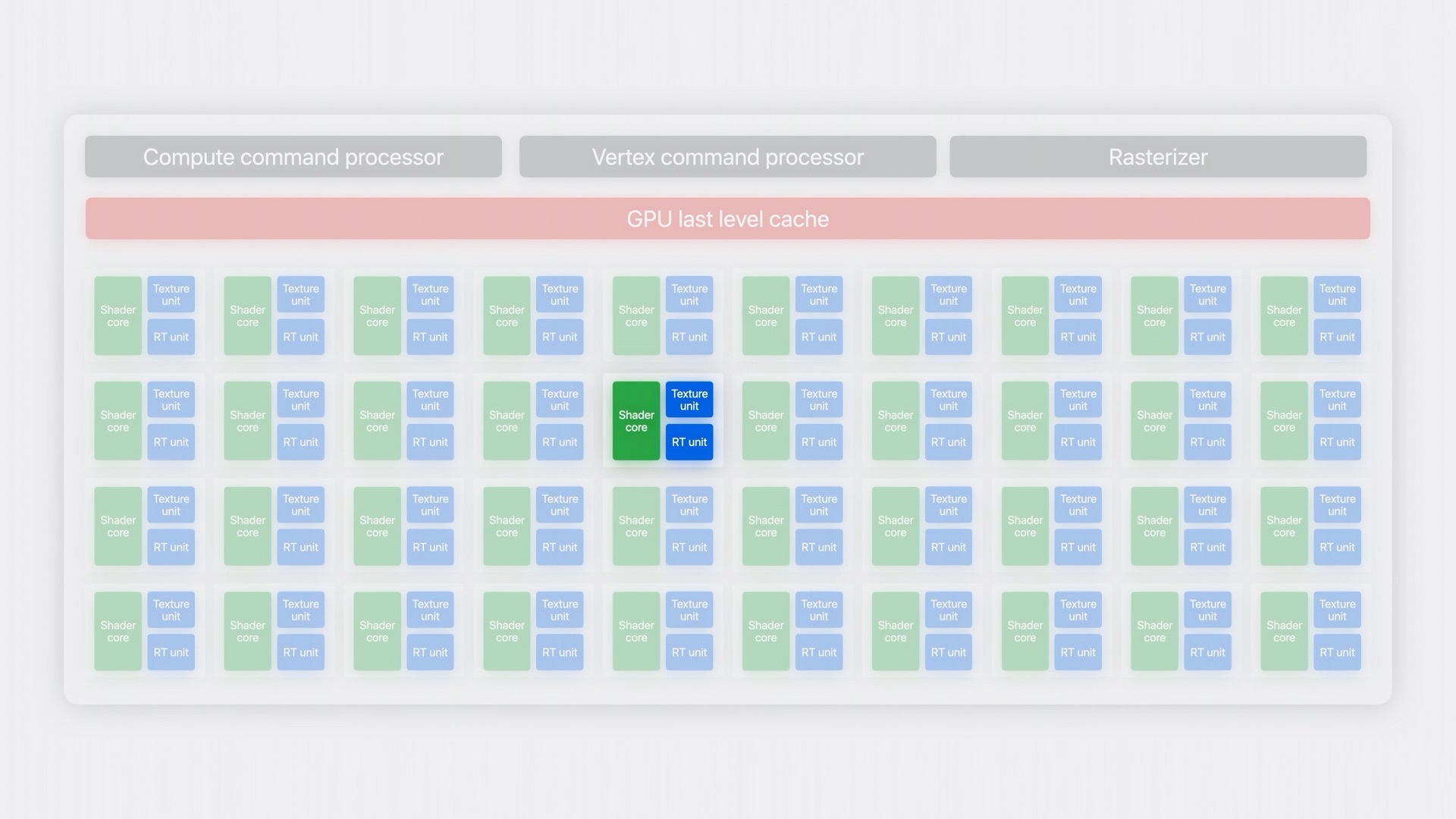
ถ้าหากแบ่งโครงสร้างส่วนต่าง ๆ ใน GPU เป็นบล็อก แยกตามการออกแบบและหน้าที่ จะได้เป็นตามภาพด้านล่างนี้
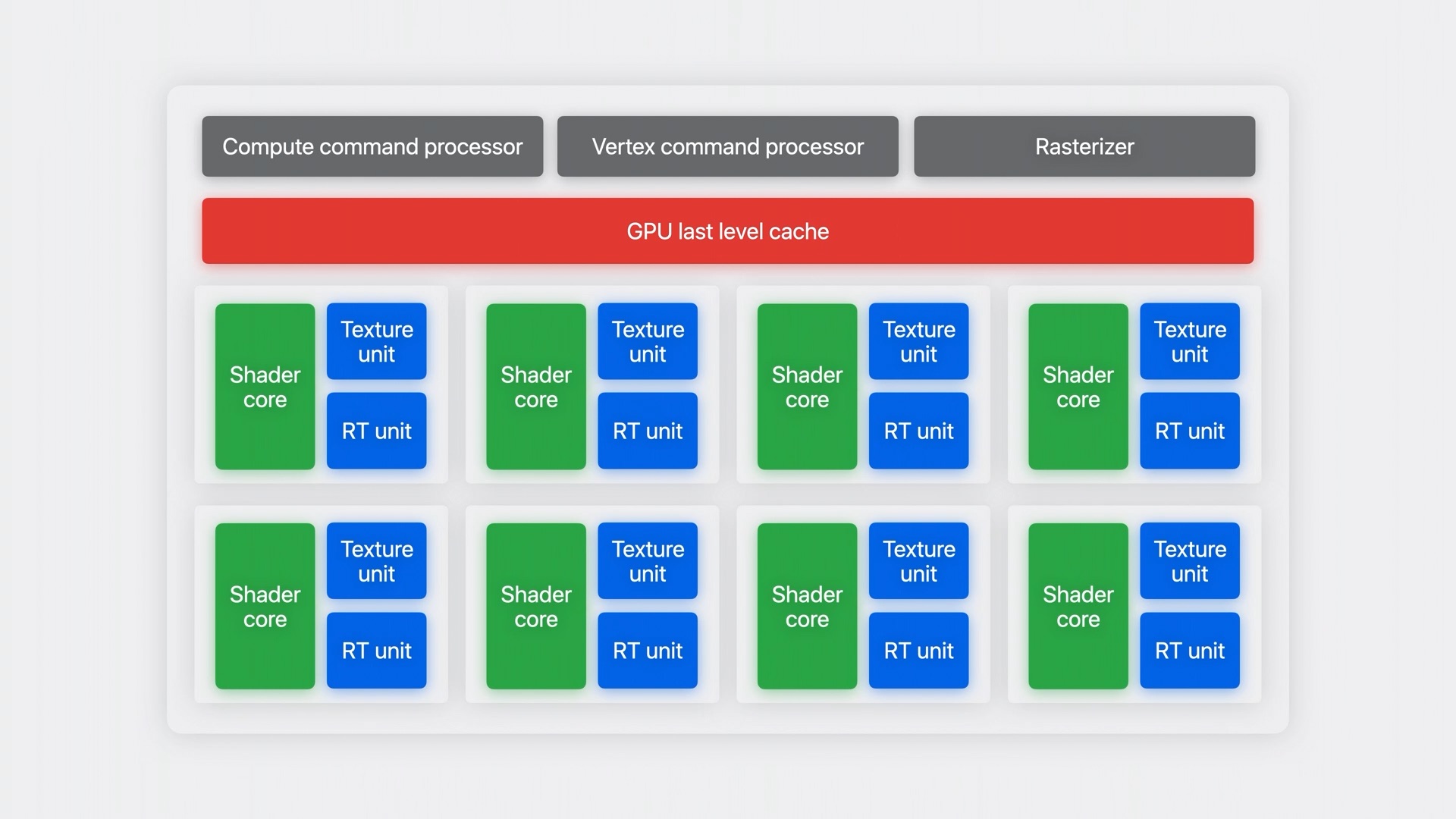
หลัก ๆ คือจะมีส่วนของบล็อกสีเทาด้านบน คือ command processor ทั้งแบบ compute และ vertex ที่ทำหน้าที่จัดการเรื่องคำสั่งจาก Metal ส่วน Rasterizer จะมาจัดการเรื่องเกี่ยวกับการเตรียม shader เพื่อการทำงานของส่วนอื่น
ถัดลงมาเป็นชุดของแคชภายใน GPU (บล็อกสีแดง) ที่เป็นแคชความจำสำหรับเก็บข้อมูลที่จำเป็นของ GPU ทั้งหมด และชุดด้านล่างทั้ง 8 กลุ่ม ภายในจะมีโครงสร้างเหมือนกันคือมี 3 ส่วนหลัก ได้แก่ Shader core ที่ใช้ในการประมวลผลคำสั่งหลักจาก Metal ทั้งหมด ทำงานควบคู่กับ Texture unit ที่ดูแลเรื่องเกี่ยวกับ texture พื้นผิวของวัตถุที่เรนเดอร์ โดยอาศัยจากไฟล์ texture ของตัวเกม
และที่สำคัญคือส่วน RT unit ที่เพิ่งเพิ่มเข้ามาใหม่ในชิปตระกูล Apple M3 และ A17 Pro เพื่อประมวลผลเกี่ยวกับ ray tracing ล้วน ๆ ในลักษณะเดียวกับการ์ดจอรุ่นอื่นในท้องตลาด นั่นจึงทำให้เครื่องแมคและ iPhone 15 Pro / Pro Max สามารถแสดงผลแสงเงาที่เขียนมาให้ใช้งาน ray tracing ได้ดีขึ้น เพราะเป็นการประมวลผลในระดับฮาร์ดแวร์โดยตรง ต่างจากก่อนหน้านี้ที่ใช้แบบซอฟต์แวร์ ซึ่งค่อนข้างกินแรง GPU ซึ่งเมื่อแยกไปประมวลผลแบบฮาร์ดแวร์แล้ว จึงทำให้เฟรมเรตในเกมสูงขึ้นกว่าเดิม โดยที่ได้ภาพสวยขึ้นด้วย แต่ในเบื้องต้นก็คือตัวเกมต้องรองรับ และที่สำคัญคือต้องมีเกมมาลงให้เล่นใน macOS / iOS ด้วย
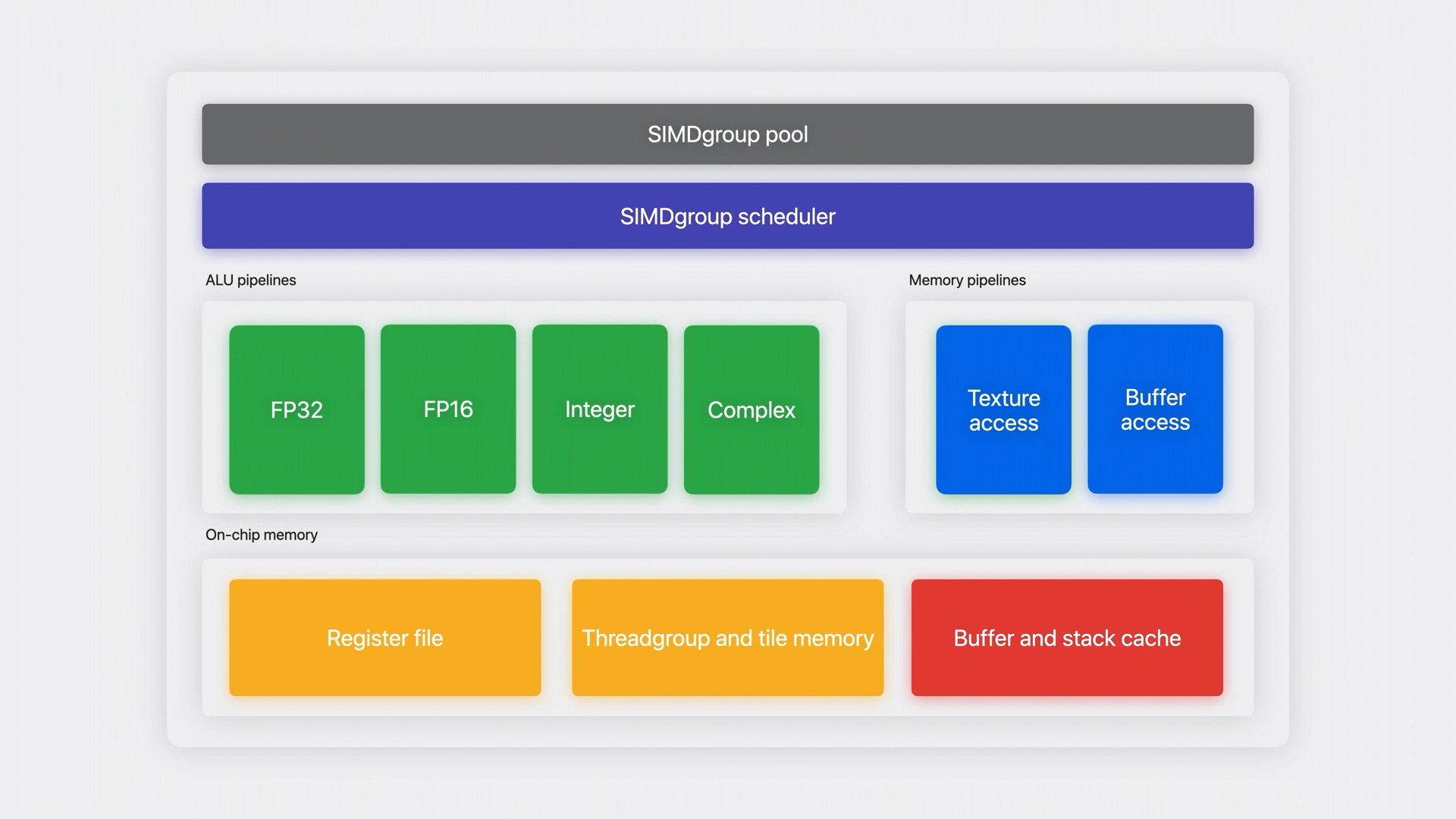
เมื่อเจาะลึกลงมาที่ shader core ภายในก็จะแบ่งเป็นส่วน ๆ ย่อยลงไปตามหน้าที่อีก ซึ่งส่วนที่น่าสนใจก็คือ ALU pipelines ที่จะแบ่งชุดสำหรับการประมวลผลทางคณิตศาสตร์และตรรกะออกตามประเภทตัวแปรเป็นทั้ง FP32, FP16, Int และ Complex ซึ่งจะแบ่งงานออกมาตามคำสั่งและข้อมูลที่ shader กำหนดมา เช่น ถ้าในการประมวลผลชุดนี้ มีส่งมาทั้ง FP32 และ Int ก็จะแยกงานออกไปประมวลผลแบบคู่ขนานกันบน ALU สำหรับ FP32 และ Int โดยตรง ส่งผลให้สามารถกระจายงานไปคำนวณได้ดีขึ้น เสมือนว่ามีถนนที่แบ่งเลนสำหรับรถประจำทาง รถบรรทุก รถยนต์ และมอเตอร์ไซค์ ทำให้รถทุกคันไม่ต้องวิ่งบนเลนเดียว เพราะถ้าวิ่งอยู่เลนเดียว รถยนต์ที่วิ่งเร็วกว่า ก็อาจจะไปไหนไม่ได้ เพราะติดรถบรรทุกที่อยู่ข้างหน้า เป็นต้น นอกจากนี้ส่วนของ Memory pipelines เองก็มีการแบ่งเป็นเส้นสำหรับการเขียน และเส้นสำหรับการอ่านข้อมูลโดยเฉพาะของทั้ง texture และการเข้าถึงข้อมูลในบัฟเฟอร์


เช่นในตัวอย่างด้านบน หากในแต่ละ SIMDgroup ของชุดคำสั่งมีการเรียกใช้คำสั่งที่ต้องการประมวลผลข้อมูลที่ต่างกัน อย่างถ้ามีทั้ง FP32 และ FP16 มาด้วยกัน แต่มีการทำงานในคนละช่วงเวลา จากแต่เดิมที่ต้องรอ ก็จะมีการจัดให้ ALU ดึงเอาคำสั่งที่ใช้ FP32 ของชุดหนึ่งและคำสั่งที่ใช้ FP16 ของชุดสองเข้าไปทำงานพร้อมกันเลย เนื่องจากทั้งสองมีการใช้ยูนิตประมวลผลคณิตศาสตร์คนละตัวกันอยู่แล้ว ทำให้สามารถทำงานโดยรวมได้เร็วกว่า นอกจากนี้ Apple ยังแนะนำให้ใช้ FP16 เป็นหลักด้วย เพราะเร็วกว่า กินหน่วยความจำน้อยกว่า เป็นต้น
สำหรับการกระจายงานไปยังไปป์ไลน์สำหรับประมวลผลให้เหมาะสม จะอาศัยการทำงานร่วมกันของ SIMDgroup pool ที่จะคอยติดตามสถานะการทำงานของชุดคำสั่งที่ทำงานอยู่ใน shader core และก็จะมี SIMDgroup scheduler ที่จะช่วยเลือกว่าจะนำชุดคำสั่งไหนมาประมวลผลเป็นลำดับถัดไป เพื่อทำให้มีการกระจายโหลดอย่างสม่ำเสมอ และเหมาะสมกับงานที่มี
บล็อกด้านล่างสุดจะเป็นส่วนของหน่วยความจำภายใน shader core เอง ที่จะใช้เก็บข้อมูลหลากหลายรูปแบบเผื่อไว้ เช่น ส่วนของ register ที่ใช้เก็บค่าตัวแปรต่าง ๆ ส่วนของ threadgroup และ tile จะใช้เก็บข้อมูลที่ใช้ร่วมกันกับ threadgroup อื่น เป็นต้น ส่วนสุดท้ายคือ buffer ที่เป็นแคชสำหรับช่วยเพิ่มประสิทธิภาพในการเข้าถึงข้อมูล

พอมองเห็นภาพรวมแล้วว่าภายใน GPU มีโครงสร้างหลัก ๆ เป็นอะไรบ้าง ทีนี้เรามาดูขั้นตอนการทำงานในส่วนต้นที่ Apple มองว่าสามารถปรับปรุงเพื่อเพิ่มประสิทธิภาพได้ ก็คือส่วนของการเริ่มประมวลผลของ shader core ที่พอเริ่มงานแล้ว จะต้องมีการไปดึงข้อมูลที่จำเป็นมาเก็บไว้ในบัฟเฟอร์ของแต่ละ SIMDgroup ก่อน จากนั้นจึงจะสามารถประมวลผลได้ อย่างในภาพด้านบนที่บ่งบอกถึงขั้นตอนการทำงานตามเวลาจากซ้ายไปขวา จะเห็นว่าเมื่อ SIMDgroup 1 จะเริ่มประมวลผล ก็จะส่งชุดคำสั่งไปยัง ALU ที่ตรงกับประเภทข้อมูล จากนั้นจึงเริ่มดึงข้อมูลที่จำเป็นเข้ามาเก็บในบัฟเฟอร์ (แท่งสีม่วง) แต่สังเกตว่าในระหว่างที่ส่งคำสั่งดึงข้อมูลออกไป (ลูกศรเส้นประสีม่วง) และเวลาที่ได้ข้อมูลกลับมา (ลูกศรสีแดง) จะเป็นช่วงที่ ALU ไม่ได้ประมวลผลอะไรเลย เพราะต้องรอข้อมูลมาส่งก่อน แล้วบางทีต้องย้อนกลับไปดึงข้อมูลถึงในแรม หรือแย่สุดคือใน SSD อันนี้คือยิ่งเหมือนเป็นการเสียเวลารอไปแบบเปล่าประโยชน์เลย เพราะจะใช้เวลารอค่อนข้างนาน

ทางทีมพัฒนาก็เลยจัดการหางานให้ ALU ครับ โดยถ้าอยู่ในช่วงที่รอข้อมูลอยู่ แล้วมี SIMDgroup คำสั่งอื่นที่เหมาะกับการใช้ ALU นี้อยู่พอดี ก็จะดึงเข้ามาเสียบเลย เพื่อให้เริ่มประมวลผลส่วนต้นของคำสั่งไปพลาง ๆ แล้วพอคำสั่งสองที่เข้ามาใหม่ต้องไปดึงข้อมูลมาเหมือนกัน สถานะของ ALU ก็จะว่างอีกครั้ง ระบบก็สามารถดึง SIMDgroup 3 เข้ามาประมวลผลช่วงต้นต่อได้พอดี แล้วพอ SIMDgroup1 ดึงข้อมูลเข้าบัฟเฟอร์ครบตามที่ต้องการแล้ว ก็ค่อยกลับไปประมวลผลคำสั่งของชุดหนึ่งต่อ ทำงานคู่กันแบบขนานไป ทำให้ ALU จะแทบไม่ว่างงานเลย โดย Apple ให้ชื่อวิธีนี้ว่าเป็น Thread Occupancy

ต่อมาก็จะคล้ายกันครับ แต่เป็นการจัดการส่วนของหน่วยความจำ register ที่ใช้ในแต่ละคำสั่งที่ส่งเข้ามาประมวลผล เนื่องจากแต่ละคำสั่งอาจมีการใช้หน่วยความจำที่ไม่เท่ากัน อย่างในภาพข้างต้นเป็นตัวอย่างโค้ดสำหรับการใส่ ray tracing ลงบนวัตถุ โดยใส่เงื่อนไขว่าถ้าพื้นผิวเป็นแก้ว ก็ใช้ฟังก์ชัน shadeGlass ที่ต้องใช้ register เก็บคำสั่งมากกว่า ซึ่งในตัวอย่างด้านบนคือใช้เต็มบล็อกเลย ส่วนคำสั่งไหนที่มีการทำงานน้อยหน่อย เช่นบรรทัดที่เป็นคอมเมนต์ของโค้ด ก็ไม่ต้องใช้ register เยอะ ทำให้ยังมีพื้นที่บน register เหลือทิ้งไว้ ไม่มีใครใช้งาน

เมื่อมองเป็นภาพใหญ่รวมกับเรื่อง thread occupancy ด้านบนที่มีการทำงานหลาย SIMDgroup แบบคู่ขนานกัน ถ้าหากแต่ละชุดคำสั่งก็มีการใช้ register แบบเหลือที่ว่างแบบภาพด้านบน ก็จะทำให้เป็นการเปลืองพื้นที่ register แบบเปล่าประโยชน์ และถ้าหาก register เต็ม ระบบก็จะไม่สามารถดึง SIMDgroup อื่นมาประมวลผลแบบคู่ขนานเพื่อใช้งาน ALU ได้เต็มประสิทธิภาพมากนัก ยิ่งถ้าเจอชุดคำสั่งที่ใช้หน่วยความจำมาก เผลอ ๆ อาจจะประมวลผลแบบคู่ขนานได้มากสุดแค่รอบละ 2 SIMDgroup ก็เต็มแล้ว ทำให้ท้ายสุดแล้วก็ยังเหลือช่วงเวลาที่ ALU ว่างอยู่ดี

จึงได้เกิดเป็นเทคนิคในการยุบรวมและจัดสรรพื้นที่ register แบบ on-chip ให้สามารถเก็บคำสั่งของคนละ SIMDgroup เอาไว้ด้วยกันได้ เพื่อให้สามารถใช้พื้นที่ได้คุ้มค่าที่สุด ทั้งยังจะเหลือพื้นที่ว่างให้ดึง SIMDgroup อื่นเข้ามาใช้งานได้ นั่นเท่ากับว่าทำให้สามารถส่งไปประมวลผลคู่ขนานบน ALU ได้มากขึ้นตามไปด้วย
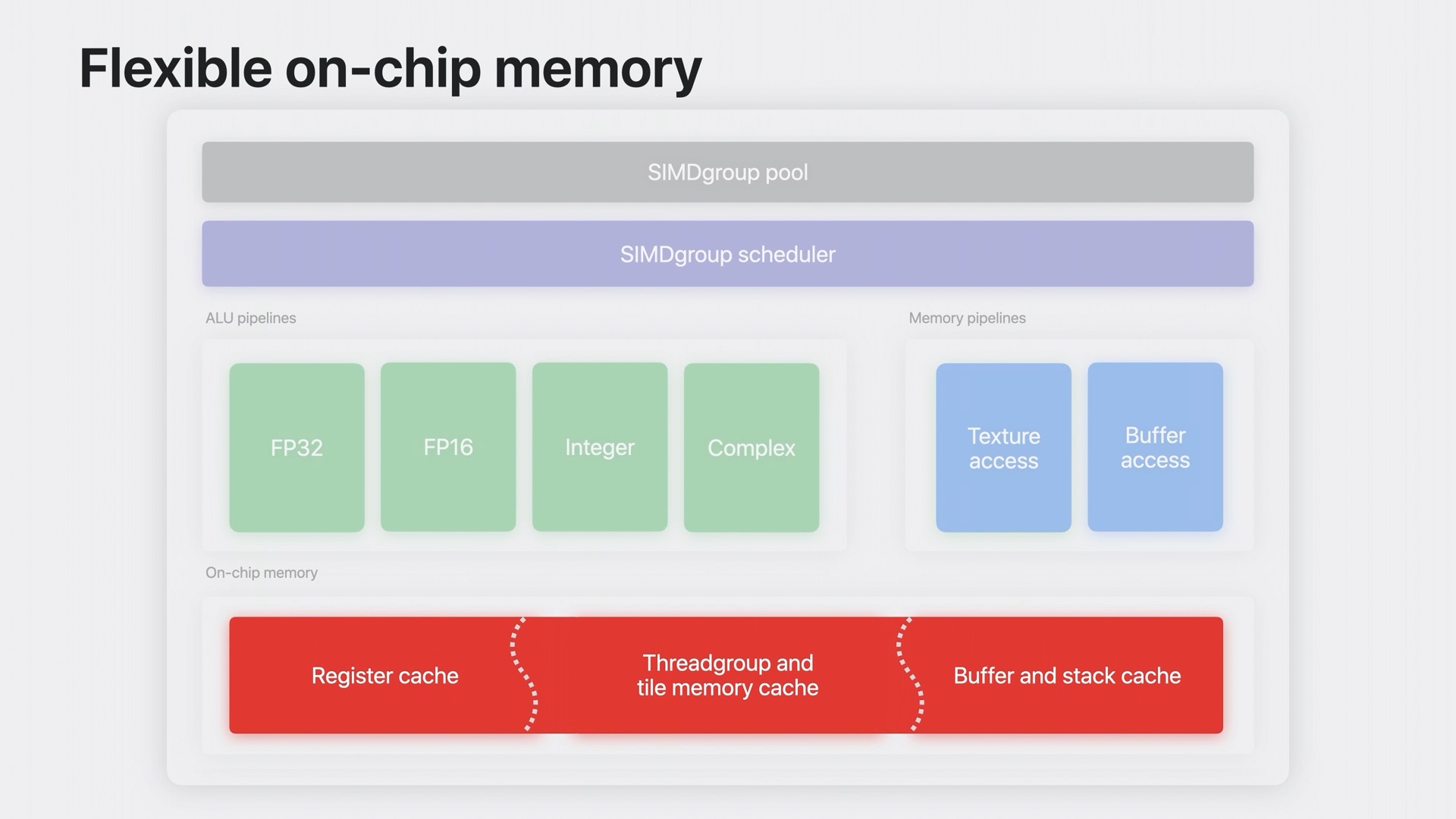
พอออกมามองที่ส่วนของหน่วยความจำ จริง ๆ แล้วก็จะมีอีกความสามารถหนึ่งที่ใส่มา ก็คือชิปสำหรับหน่วยความจำแต่ละแบบ สามารถเปลี่ยนหน้าที่ตัวเองเป็นแคชให้ชั่วคราวได้ นั่นทำให้ระบบสามารถส่งข้อมูลไปเก็บบนหน่วยความจำประเภทอื่น เช่น threadgroup และ tile ได้ในกรณีที่จำเป็น
ข้อดีสำหรับการออกแบบหน่วยความจำแบบ on-chip ในลักษณะนี้ก็คือ
1) ช่วยให้สามารถออกแบบชิปที่มีหน่วยความจำแคชน้อยสำหรับเก็บข้อมูลทุกประเภทลงได้ เพราะใช้แบบแยกหน้าที่ ที่ก็ยังสามารถเปลี่ยนตัวเองกลับเป็นแคชชั่วคราวได้อยู่
2) ช่วยให้มีการกระจายการเก็บข้อมูลลงในหน่วยความจำต่าง ๆ ได้ดีขึ้น ทำงานได้เต็มศักยภาพกว่า เนื่องจากบางชุดคำสั่งอาจจะเรียกใช้หน่วยความจำแค่ประเภทใดประเภทหนึ่งเท่านั้น ไม่เรียกใช้อีกประเภทเลย ถ้าเป็นในอดีตก็คือจะต้องจัดสรรไปใช้แบบแรกอย่างเดียว ส่วนหน่วยความจำแบบที่สองก็ปล่อยให้ว่างงานไป แต่ในสถาปัตยกรรมแบบชิป M3 และ A17 Pro จะช่วยให้สามารถเกลี่ยหน้าที่ออกไปได้อย่างทั่วถึง และมีพื้นที่ในการรับข้อมูลที่เยอะกว่าเดิม

และไม่ใช่แค่นั้น แต่ในกรณีที่แอปหรือเกมต้องการพื้นที่เก็บข้อมูลของแต่ละคำสั่งมากกว่าปกติ GPU ก็ยังสามารถโยกข้อมูลให้ไปเก็บในแคชของ GPU เองได้ หรือแม้กระทั่งโยกไปเก็บไว้ในหน่วยความจำหลักของเครื่อง (แรม) ได้ด้วย ซึ่งทั้งหมดจะเป็นหน้าที่ของ shader core ในการพิจารณาว่าจะมีการปรับใช้หน่วยความจำแบบไหน อัดงานให้ thread อย่างไรถึงจะเหมาะสม โดยเบื้องต้นจะเน้นให้ใช้การเก็บข้อมูลไว้ใน GPU เป็นหลัก และให้ไปป์ไลน์ประมวลผลทำงานอยู่อย่างสม่ำเสมอ แต่ถ้าหากนักพัฒนาต้องการจะเข้ามาจัดการส่วนนี้เองก็สามารถทำได้เช่นกัน
การจัดการเรื่อง ray tracing

ในหัวข้อนี้จะค่อนข้างหนักไปทางเรื่องการจัดการโค้ดนะครับ เลยจะใช้การพูดถึงแค่กระบวนการที่ใช้เพื่อเพิ่มประสิทธิภาพของการทำ ray tracing ในภาพแทน
โดยปกติแล้วในการทำ RT เพิ่มเข้ามาในภาพ GPU จะต้องรับคำสั่ง ray มา แล้วยิงแสงไปตกกระทบบนวัตถุที่เรนเดอร์ จากนั้นก็มาคำนวณว่าจุดที่ตกกระทบจะต้องแสดงภาพออกมาอย่างไร สะท้อนไปตรงไหน มีเงาลักษณะแบบใด ซึ่งใน Metal API ก็จะมีส่วนของ Intersector ที่ทำหน้าที่ในส่วนนี้ ซึ่งนอกจากจะส่งผลถึงความสวยงามของภาพแล้ว ยังมีผลกับประสิทธิภาพโดยรวมอีกด้วย สำหรับขั้นตอนการทำงานของส่วนนี้ จะต้องมีการประมวลผลเพื่อหาวัตถุที่จะมีแสงตกกระทบในภาพ จากนั้นก็ใช้ฟังก์ชันเรื่องการ intersect ที่แอป/เกมอาจมีมาให้ หรือจากของ API เอง แล้วถ้าผลออกมาโอเค ก็นำไปใช้กับส่วนอื่นที่เป็นลักษณะเดียวกันด้วย ซึ่งทั้งสามขั้นตอนนี้จะทำงานแบบวนลูป ไปจนกว่าจะเจอผลลัพธ์ที่ใกล้เคียงที่สุด และนำผลนั้นไปใช้งานต่อในการคำนวณและการแสดงผลอีกที แน่นอนว่ากระบวนการนี้ทำที่ระดับฮาร์ดแวร์ครับ เพราะในชิป M3 และ A17 Pro นั้นมี RT unit อยู่ในแต่ละ shader core ของ GPU แล้ว
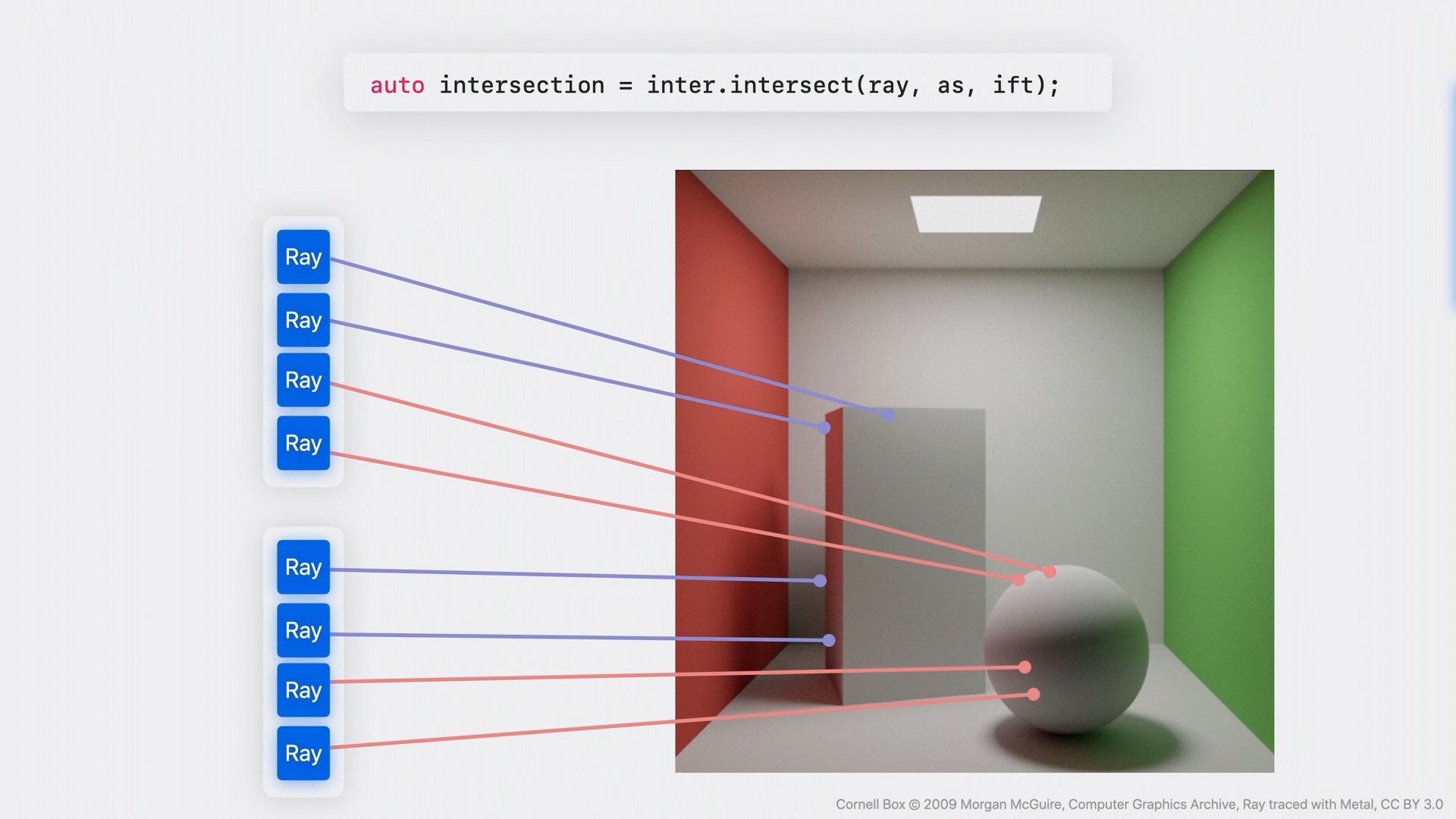
อย่างในภาพด้านบนนี้ จะมีการแบ่ง SIMDgroup ออกเป็นสองกลุ่มทำงานคู่ขนานกัน โดยใช้คำสั่งแบบอัตโนมัติ แต่ละเส้นที่โยงจาก Ray มายังภาพคือโค้ดที่ระบุให้ยิงแสงไปตกกระทบบนวัตถุ แล้วให้มีการคำนวณว่าจะมีสภาพแสง เงาและการสะท้อนอย่างไร เส้นสีม่วงคือยิงไปหากล่องสี่เหลี่ยมซึ่งถูกระบุในโค้ดโดยใช้จากที่มีอยู่แล้วใน Metal API ซึ่งระบบก็จะทำงานได้ง่ายกว่า เพราะมีข้อมูลอยู่แล้ว ส่วนเส้นสีชมพูที่ยิงไปหาลูกบอลซึ่งสร้างมาจากฟังก์ชันเพิ่มเติมที่ไม่มีใน API โดยมีการกำหนดลักษณะขึ้นมาตามต้องการ จึงอาจต้องใช้เวลาในการ intersect มากกว่าหน่อย
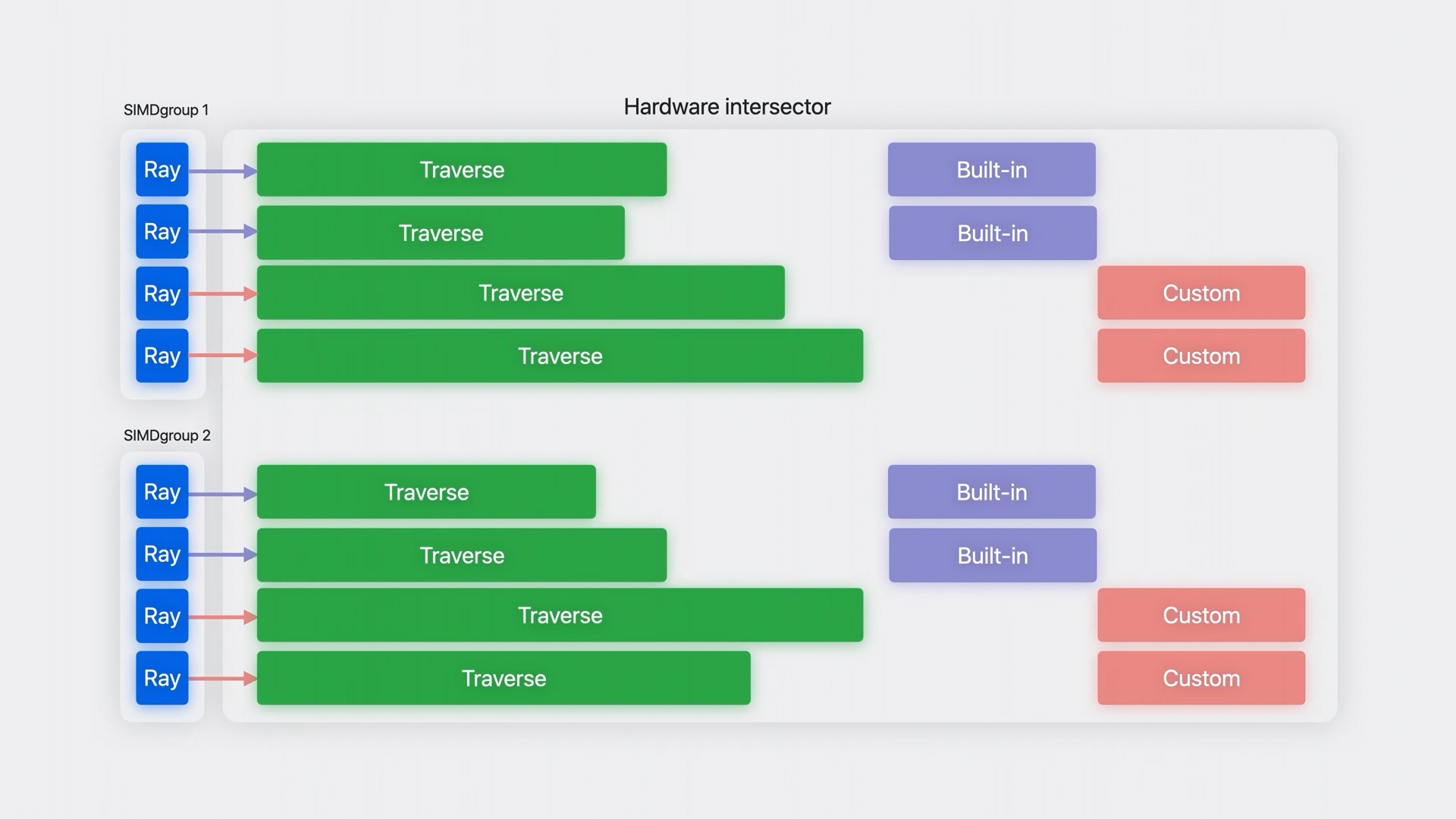
ถ้านำกระบวนการทำงานมาวางแบบไทม์ไลน์จะได้แบบภาพข้างบนครับ แม้ว่าจะทำงานแบบคู่ขนานกันแล้วก็จริง แต่ในขั้นตอนการตรวจสอบวัตถุและทดสอบเรื่องแสงของแต่ละจุด (Traverse) อาจใช้เวลาไม่เท่ากันก็ได้ ทำให้เธรดที่ traverse เสร็จแล้วก็ต้องรอจนกว่าเธรดอื่นใน SIMDgroup เดียวกันจะทำเสร็จ จึงจะขยับไปขั้นตอนการ intersect และขั้นตอนอื่นในลำดับถัดไปได้ จะเห็นว่ามันค่อนข้างคล้ายกับเรื่อง thread occupancy ใน shader core เลยครับ คือมันมีช่องว่างที่ต้องรอแบบเปล่าประโยชน์อยู่
แล้วพอเข้าสู่การ intersect แต่ละเธรดใน SIMDgroup เดียวกันก็มีการใช้คำสั่งในการ intersect ที่ต่างกัน สีม่วงคือมีคำสั่งใน API อยู่แล้ว ส่วนสีชมพูคือเป็นคำสั่งที่มาจากแอป/เกม ทำให้เกิดการรอในการประมวลผลของแต่ละ SIMDgroup เองด้วย เพราะจะได้โหลดคำสั่งมาทำแบบเดียวก่อนชุดนึง ส่วนอีกชุดก็ค่อยโหลดมาทำเป็นล็อตเดียวกัน แต่ถ้าเกิดว่า SIMDgroup อื่น เขาก็ต้องใช้คำสั่งเดียวกันเหมือนกันล่ะ??
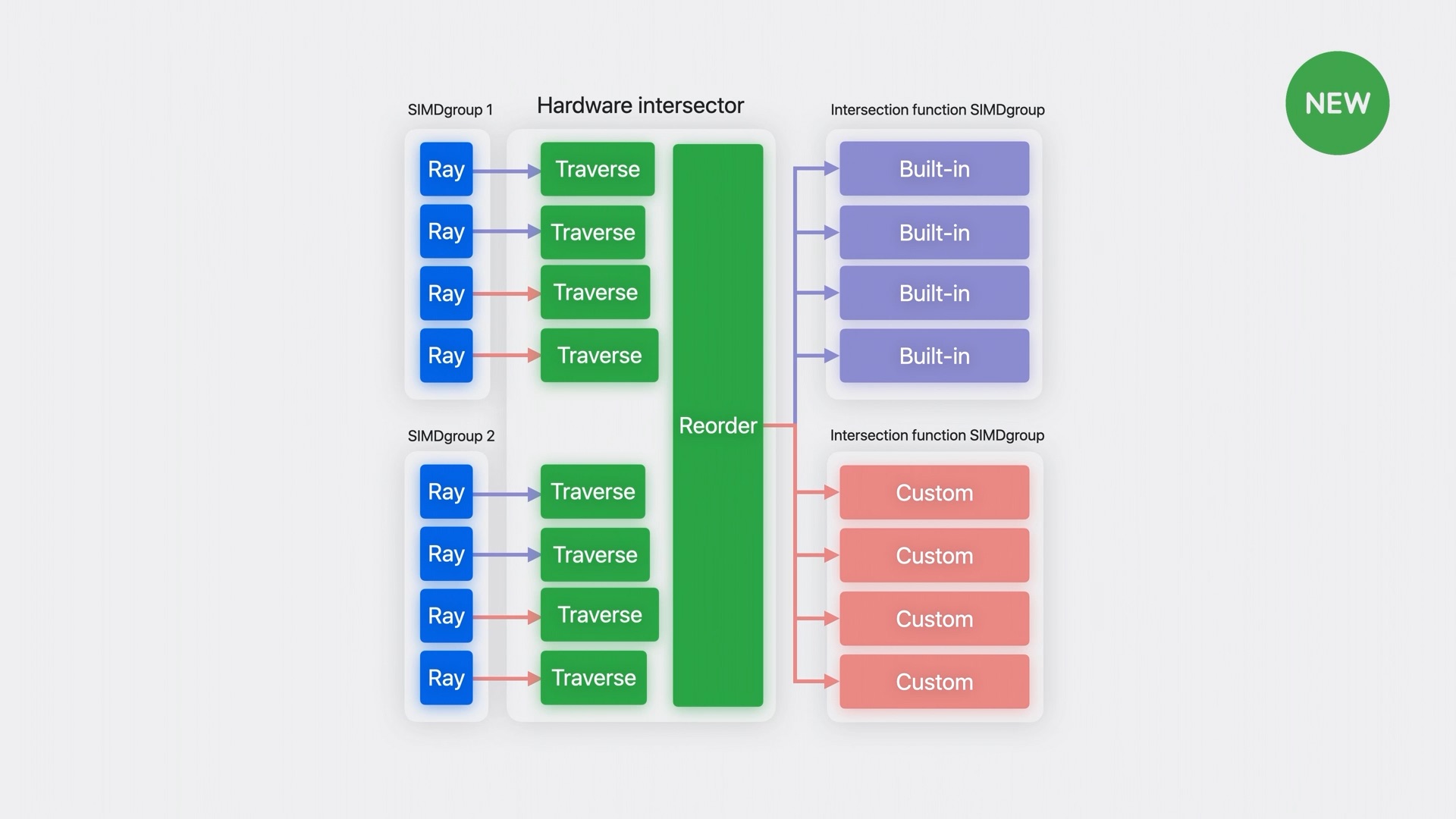
วิธีที่ช่วยลดการรอเพื่อเพิ่มประสิทธิภาพที่ Apple เลือกใช้ หนึ่งคือการให้ฮาร์ดแวร์เป็นตัวประมวลผลงานส่วนนี้ ซึ่งก็ช่วยเพิ่มความเร็วในการ traverse ได้มากแล้ว แต่ยังมีการเพิ่มขั้นตอนการ Reorder เข้ามาแทรกตรงกลางด้วย เพื่อช่วยจัดเอาเธรดที่ใช้คำสั่ง intersect เดียวกัน จากแหล่งเดียวกันมาไว้ด้วยกัน เพื่อให้ประมวลผลได้ในชุดเดียวทั้งหมด ซึ่งจะช่วยลดระยะเวลาในการรอไปได้อีกเยอะ
การปรับปรุงเรื่อง mesh shading

ส่วนของกระบวนการ mesh shading ซึ่งเป็นส่วนหนึ่งของขั้นตอนการเรนเดอร์ภาพ 3 มิติ จะใช้การคำนวณเพื่อสร้างวัตถุแบบ 3 มิติขึ้นมา โดยอาศัยการประกอบกันของรูปสามเหลี่ยมจำนวนมากขึ้นมาเป็นรูปร่าง เข้ามาแทนที่กระบวนการแบบ vertex shader ที่ใช้มาอย่างยาวนาน จุดเด่นคือมีความยืดหยุ่นในการทำงานมากกว่า
ซึ่งในชิป A17 Pro และ M3 series ก็มีการปรับปรุงในเชิงเทคนิคให้มีการใช้เลนของหน่วยความจำที่ลดลงกว่ารุ่นก่อนหน้า รวมถึงฝั่งซอฟต์แวร์เองก็มีการเพิ่ม API เข้ามาช่วยเพิ่มประสิทธิภาพด้วย เช่น การทำให้สามารถเข้ารหัสคำสั่งในการวาด mesh ได้แบบคู่ขนานบน GPU เลย รวมถึงยังเพิ่มขีดความสามารถให้สามารถสร้าง threadgroup ต่อตาราง mesh ได้สูงขึ้น จากเดิมที่ทำได้ 1,024 กลุ่ม เพิ่มเป็นมากกว่า 1 ล้านกลุ่ม
ทั้งหมดนี้ก็คือ 3 ประเด็นทางเทคนิคหลัก ๆ ที่ Apple เปิดเผยออกมาว่ามีการปรับปรุง GPU อย่างไรบ้างในชิป M3 series ที่อยู่ในเครื่องแมคและ A17 Pro ที่อยู่ใน iPhone 15 Pro series จุดหลักเลยก็คือเป็นการปรับปรุงกระบวนการทำงานให้ทำงานได้เต็มศักยภาพ ให้ประสิทธิภาพต่อวัตต์พลังงานที่ใช้ดีขึ้น ซึ่งน่าจะมีส่วนเข้ามาช่วยให้แต่ละเครื่องรองรับการประมวลผลด้านกราฟิกได้ดี สู่กับคู่แข่งในท้องตลาดได้ใกล้เคียงกว่าเดิม และที่สำคัญสำหรับฝั่งผู้ใช้งานก็คือมีความสามารถในการเล่นเกมได้ดีกว่าที่เคย ไปจนถึงสายที่ต้องใช้งานด้านกราฟิก การเรนเดอร์ต่าง ๆ โดยสามารถเข้าไปชมคลิปเต็มได้ที่นี่
แต่อย่างไรก็ตาม ก็ต้องขึ้นอยู่กับทางนักพัฒนาซอฟต์แวร์และเกมด้วย ว่าจะลงทุนในการพัฒนาบนแพลตฟอร์มของ Apple หรือมีความตั้งใจจะพอร์ตเกมมาลงมากขนาดไหน เพราะเทคโนโลยีเองก็เริ่มไล่เจ้าตลาดเข้ามาแล้ว ที่เห็นได้ชัดก็คือการรองรับ ray tracing ได้บน iGPU เลย รวมถึงฝั่งของ Apple เองก็มีการเตรียมเครื่องมือไว้ให้ในระดับหนึ่ง และในงานเปิดตัว iPhone 15 เมื่อปลายปีก็มีการประกาศไลน์อัปเกมระดับ AAA ที่จะมาลงให้เล่นใน iOS แน่ ๆ ได้แก่ Resident Evil Village, Resident Evil 4 Remake, Death Stranding, Assassin’s Creed Mirage และ The Division Resurgence ซึ่งตัวของ RE: Village เองก็เปิดให้เล่นไปแล้วด้วย จึงพอน่าสนใจว่าการเล่นเกมในแมคน่าจะทำได้ดีขึ้นมากแล้วจริง ๆ












