


การเกทับกันไปมาในวงการเทคโนโลยีเมื่อมีการพัฒนาเทคโนโลยีที่ดีกว่าผู้อื่นได้ถือเป็นเรื่องธรรมดาสามัญที่เราสามารถพบเจอได้ทั่วไปครับ เหตุผลนั้นก็อาจจะเพราะว่าส่วนหนึ่งแต่ละบริษัทเองก็ต้องการที่จะโฆษณาเทคโนโลยีที่ตัวเองกำลังพัฒนาอยู่ รวมไปถึงพยายามชักจูงให้ผู้ใช้(ซึ่งในที่นี้อาจจะหมายถึงลูกค้าที่จะซื้อเทคโนโลยีนั้นไปใช้งาน) ทำการซื้อเทคโนโลยีของบริษัทตัวเองไปใช้งานมากกว่า ล่าสุดในช่วงไม่นานผ่านมานี้ทาง Microsoft ได้เผยผลงานทางด้านวิชาการทางด้านการวิจัยการประเมินแยกมนุษย์ออกจากโปรแกรมด้วยการใช้ภาพออกมาครับ
![]()
จากผลงานการวิจัยที่ทาง Microsoft ตีพิมพ์ออกมานั้นก็เรียกได้ว่าเป็นการเกทับ Baidu ที่ได้ตีพิมพ์ผลงานวิจัยในลักษณธเดียวกันออกมาก่อนหน้านี้ไม่นานมากนักครับ โดยหากอ้างอิงจากเอกสารงานวิจัยของทาง Microsoft พบว่าเปอร์เซ็นต์ความผิดพลาดในการประเมินแยกมนุษย์ออกจากโปรแกรมจากก่อนหน้านี้ที่เคยใช้ข้อมูล ImageNet dataset มีเปอร์เซ็นต์ความผิดพลาดอยู่ที่ 5.1% แต่การวิจัยรูปแบบใหม่นั้นพบว่าการประเมินแยกมนุษย์ออกจากโปรแกรมมีเปอร์เซ็นต์ความผิดพลาดลดลงเหลือแค่ 4.94% ในขณะที่งานวิจัยของทาง Baidu นั้นมีเปอร์เซ็นต์ความผิดพลาดอยู่ที่ 5.98% ครับ

แน่นอนว่าก่อนหน้านี้ก็มีงานวิจัยในรูปแบบของ Google ตีพิมพ์ออกมาในปี 2014 ครับ โดยงานวิจัยของทาง Google นั้นมีเปอร์เซ็นต์ความผิดพลาดอยู่ที่ 6.66% ดังนั้นทาง Microsoft จึงเคลมได้อย่างเป็นทางการครับว่าขั้นตอนวิธีที่ Microsoft ใช้ในการประเมินแยกมนุษย์ออกจากโปรแกรมด้วย ImageNet dataset นั้นมีความถูกต้องมากที่สุดในโลก(ในเวลานี้) อย่างไรก็ตามไม่ได้หมายความว่างานวิจัยของทาง Microsoft นั้นจะไม่มีข้อผิดพลาดครับ เพราะทาง Microsoft ได้บอกเอาไว้ว่าการประเมินแยกมนุษย์ออกจากโปรแกรม ขึ้นอยู่กับระดับความรู้และพื้นฐานของความเข้าในในชุดรูปภาพของมนุษย์คนนั้นๆ ด้วยเช่นเดียวกัน ซึ่งสิ่งนี้เป็นปัจจัยที่ทาง Microsoft ต้องหาทางแก้ไขต่อไปครับ
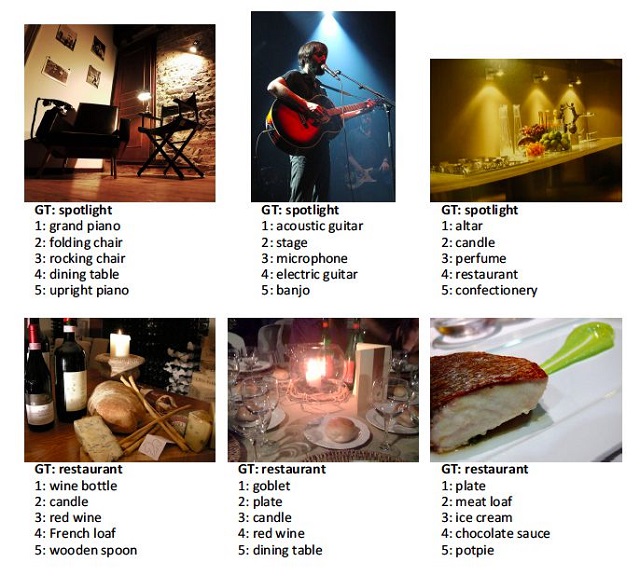
ตัวอย่างของความผิดพลาดที่จะเกิดขึ้นได้นั้นก็เป็นไปดังรูปทางด้านบนครับ อย่างเช่นรูปที่อยู่ตรงกลางที่เป็นนักร้องยืนร้องเพลงและดีดกีตาร์ไปด้วยซึ่งมนุษย์ที่มีความเข้าใจแตกต่างกันไปนั้นอาจจะมีคำตอบที่แตกต่างกันไปซึ่งหากดูที่คำตอบ 1 – 5 แล้วเรียกได้ว่าทุกคำตอบนั้นก็ถูกหมดสำหรับรูปนั้น แต่ในกรณีของ Microsoft นั้นจะมีการใช้รูปภาพเป็นชุดที่มีความแตกต่างกันแต่มีสิ่งหนึ่งที่เหมือนกันอยู่ซึ่งนั่นจะทำให้มนุษย์สามารถที่จะเลือกคำตอบที่ถูกต้องได้มากที่สุดครับ(แน่นอนว่าหากเป็นโปรแกรมแล้วก็จะไม่สามารถที่จะทำการแยกได้ครับว่าภาพชุดนั้นมีสิ่งใดที่เหมือนกัน แต่ด้วยผลลัพธ์ที่ยังคงมีเปอร์เซ็นต์ความผิดพลาดอยู่ทำให้เห็นได้ว่ายังมีบางชุดภาพที่ไม่เหมาะสมในการนำมาใช้เป็นข้อมูลครับ)
อีกสาเหตุสำคัญที่ทำให้เกิดเปอร์เซ็นต์ความผิดพลาดในการประเมินแยกมนุษย์ออกจากโปรแกรมนั้นก็คือโปรแกรมคอมพิวเตอร์นั้นสามารถที่จะทำการเรียนรู้ข้อผิดพลาดเพื่อที่จะทำการอัพเดทข้อมูลให้กับตัวเองได้ด้วยครับ(หรือที่เรารู้จักกันในระบบปัญญาประดิษฐ์ที่เรียกว่า AI ซึ่งลึกลงไปกว่านั้นจะเรียกว่า Machine Learning) ซึ่งนั่นทำให้โปรแกรมสามารถทำการเลือกข้อมูลใหม่ได้หากเจอกับเซ็ทของภาพข้อมูลเก่าๆ ซึ่งก็เป็นปัญหาที่ทาง Microsoft จะต้องทำการแก้ไขต่อไปเช่นเดียวกันครับ
ที่มา : gigaom